판다스에는 데이터 프레임을 변형할 수 있는 여러가지 방법이 있다.
Pivot
pivot()
자료들은 보통 "Record"나 "Wide" 포맷으로 되어있다.
이 포맷은 하나의 레코드가 여러 컬럼마다 하나의 값을 가지는 형식인데,
이를 피벗화 해주면 컬럼 별 레코드를 확인할 수 있다.
예를들어, "시간 별 컬럼 1의 변화량"을 보고 싶다면 pivot을 활용하면 편리하다.

이를 파이썬을 활용해 구하면 아래와 같다.
df_pivoted = df.pivot(index="date", columns="variable", values="value")
##outcome
variable A B C D
date
2020-01-03 0 3 6 9
2020-01-04 1 4 7 10
2020-01-05 2 5 8 11
pivot_table()
pivot()이 저런 일반적인 피벗화를 수행한다면, pivot_table()은 aggregation을 같이 수행해준다.
pd.pivot_table(
df,
values=["D", "E"], # D값과 E 값의
index=["B"], # B를 기준으로
columns=["A", "C"], #컬럼 A, C를 사용해서
aggfunc="sum", # 총합을 보여주기
)
Stack
stack()
pivot과도 비슷하지만, stack의 경우 멀티 인덱스 데이터에 더 적절하다고 할 수 있다.

df_stacked = df.stack(future_stack=True)
unstack()
unstack은 stack을 거꾸로 해주는 메쏘드이다.

df_unstacked = stacked.unstack(0)
df_unstacked = stacked.unstack("first")
컬럼명이나 인덱스 레벨을 활용해서 unstack해줄 수도 있다.
stack과 unstack은 value값들을 sort 해주는 과정을 거치기 때문에,
stack 후 unstack을 하면 index를 sorting하는 결과를 낳는다.
all(df.unstack().stack(future_stack=True) == df.sort_index())
Out: True
시각화
데이터프레임으로 Bar Plot을 그릴 때, stack을 사용하면 변수들이 쌓인 형태로 시각화할 수 있다.
import pandas as pd
month = [ 'Jan','Feb','Mar','Apr','May','Jun','Jul','Aug','Sep','Oct','Nov','Dec' ]
data = {
"Banana":[52, 83, 82, 53, 99, 94, 83, 74, 87, 70, 63, 74],
"Orange":[99, 71, 77, 57, 87, 50, 59, 58, 63, 76, 51, 88],
"mango":[50, 71, 93, 82, 70, 58, 55, 97, 76, 52, 97, 83],
}
df = pd.DataFrame(data,index=month)
df.plot(kind="bar",stacked=True,figsize=(15,10))
for c in ax.containers:
labels = [ x.get_height() for x in c ]
ax.bar_label(c, labels=labels, label_type='center')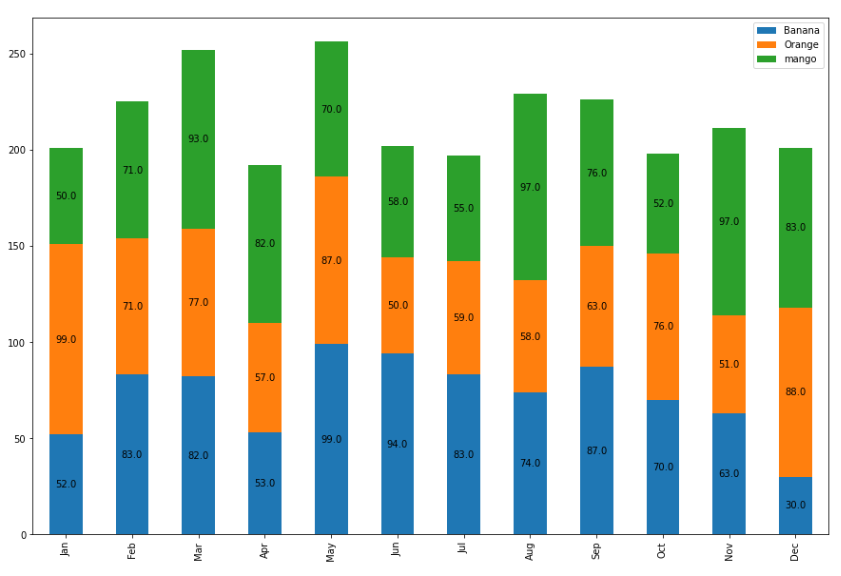
Melt
melt()
melt 역시 데이터 프레임 변형에 쓰이는 메쏘드이며,
Identifier 컬럼이 1개 이상 이고, 나머지가 전부 Value 컬럼일 경우 유용하게 쓰일 수 있다.
## 아래 처럼 value 컬럼을 새로 만들어준다.
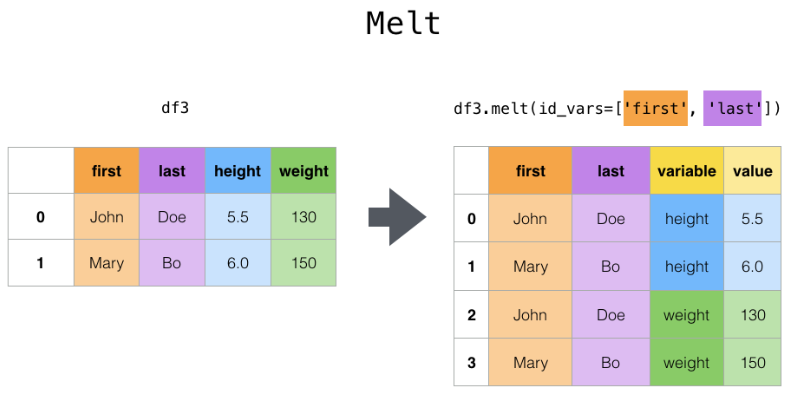
이를 파이썬으로 활용하면 아래와 같다.
# melt는 기본적으로 index를 무시한다.
df_melted = df.melt(id_vars=["first", "last"])
# 이렇게만 해도 알아서 정리를 해줌
Out:
first last variable value
0 John Doe height 5.5
1 Mary Bo height 6.0
2 John Doe weight 130.0
3 Mary Bo weight 150.0
df_melted = df.melt(id_vars=["first", "last"], var_name="quantity", ignore_index=False)
Out:
first last quantity value
0 John Doe height 5.5
1 Mary Bo height 6.0
2 John Doe weight 130.0
3 Mary Bo weight 150.0
wide_to_long()
이 메소드는 melt와 비슷하지만, 사용자가 재량 껏 테이블을 커스텀할 수 있다.
pd.wide_to_long(df, ["A", "B"], i="id", j="year")
Out:
X A B
id year
0 1970 1.519970 a 2.5
1 1970 -0.493662 b 1.2
2 1970 0.600178 c 0.7
0 1980 1.519970 d 3.2
1 1980 -0.493662 e 1.3
2 1980 0.600178 f 0.1
Dummies
get_dummies()
dummies의 경우 DataFrame이 아닌 범주형 Series를 "dummy" 형태, 혹은 "indicator" 형태로 변환할 때 쓴다.
범주형 데이터들을 0과 1로 표현해주는 "원 핫 인코딩"을 생각하면 된다.
df["key"].str.get_dummies()
Out:
a b c
0 0 1 0
1 0 1 0
2 1 0 0
3 0 0 1
4 1 0 0
5 0 1 0
dummies = pd.get_dummies(df["key"], prefix="key")
df[["data1"]].join(dummies)
Out:
data1 key_a key_b key_c
0 0 False True False
1 1 False True False
2 2 True False False
3 3 False False True
4 4 True False False
5 5 False True False
from_dict = pd.get_dummies(df, prefix={"B": "from_B", "A": "from_A"})
# prefix custom
prefix = 'key'를 활용하면 더미컬럼마다 key가 들어가고
기존 데이터에 merge 하는 데 도움이 된다.
pd.get_dummies(s, drop_first=True)
drop_first = True를 해주면
첫 컬럼을 없애주어 Collinearity를 없애줄 수 있다.
자유도와 비슷한 개념으로, n - 1개의 컬럼의 값이 정해지면 마지막 컬럼의 값도 따라 정해진다.
from_dummies()
from_dummies는 더미 데이터를 본래 데이터프레임으로 바꿔준다.
df = pd.DataFrame({"prefix_a": [0, 1, 0], "prefix_b": [1, 0, 1]})
Out:
prefix_a prefix_b
0 0 1
1 1 0
2 0 1
pd.from_dummies(df, sep="_")
Out:
prefix
0 b
1 a
2 b
기타
explode()
nested values 처럼 복잡한 구조의 value들을 확인할 수 있는 함수
keys = ["panda1", "panda2", "panda3"]
values = [["eats", "shoots"], ["shoots", "leaves"], ["eats", "leaves"]]
df = pd.DataFrame({"keys": keys, "values": values})
Out:
keys values
0 panda1 [eats, shoots]
1 panda2 [shoots, leaves]
2 panda3 [eats, leaves]
df["values"].explode()
Out:
0 eats
0 shoots
1 shoots
1 leaves
2 eats
2 leaves
Name: values, dtype: objectcrosstab()
여러 값들을 가진 컬럼 중 2개의 컬럼을 뽑아 confusion table 처럼 n x n의 테이블을 만들어준다.
df = pd.DataFrame(
{"A": [1, 2, 2, 2, 2], "B": [3, 3, 4, 4, 4], "C": [1, 1, np.nan, 1, 1]}
)
Out:
A B C
0 1 3 1.0
1 2 3 1.0
2 2 4 NaN
3 2 4 1.0
4 2 4 1.0
pd.crosstab(df["A"], df["B"])
Out:
B 3 4
A
1 1 0
2 1 3
'오늘 나는 (TIL)' 카테고리의 다른 글
| [TIL 240906] 딥러닝 속 ANN (Artificial Neural Network)과 GA (Genetic Algorithm) (0) | 2024.09.06 |
|---|---|
| [TIL 240903] Tableau의 예측 프로세스 속 이동 평균과 평활법 (2) | 2024.09.03 |
| [TIL 240820] 머신러닝 10가지 알고리즘 (0) | 2024.08.20 |
| [TIL 240816] 데이터 분석가의 커뮤니케이션 (0) | 2024.08.16 |
| [TIL 240814] 분산분석 ANOVA 검정과 다중 검정의 문제 (0) | 2024.08.13 |