분석 결과
1. 고객 별 군집
머신러닝 군집 모델 선발
우리는 기본적으로 k-means 머신러닝 알고리즘을 통해 군집화 분석을 진행했으며,
전처리된 RFM을 통해 군집화를 진행하기 앞서,
더 나은 모델을 선발하기 위해 기준점을 잡기 위해
전처리 (Transfomation 및 Scaling)가 되지 않은 RFM의 모델 성능을 먼저 확인해보았다.


이 때 최고 실루엣 점수는 k=3일 때 0.337이었으며, 군집의 시각화도 위와 같았다.

우리는 나아가 분석가의 재량 하에 유연성을 보이는 RFM 군집법의 특성을 이용해
각각의 R, F, M에 따로 가중치를 주었다.
이 중 Frequency의 경우, 그 쏠림이 제일 심했으며,
우리는 이를 완화하기 위해 곱해준 "도시 별 인구수" 데이터가 군집 시 너무 큰 영향을 주지 않길 바랬고,
적절한 가중치를 찾기위해 여러 가중치 별 실루엣 점수를 확인해 보았다.
| R_weight | F_weight | M_weight | K | Silhouette Score | |
| Vanilla | 1 | 1 | 1 | 3 | 0.337 |
| W_1 | 0.6 | 1.3 | 1.3 | 3 | 0.313 |
| W_2 | 1.5 | 1 | 1 | 4 | 0.429 |
| W_3 | 1.6 | 0.2 | 1.6 | 4 | 0.479 |
이 결과 세 번째 웨이트 모델이 k = 4일 때 0.479로 실루엣 점수가 제일 높았다.
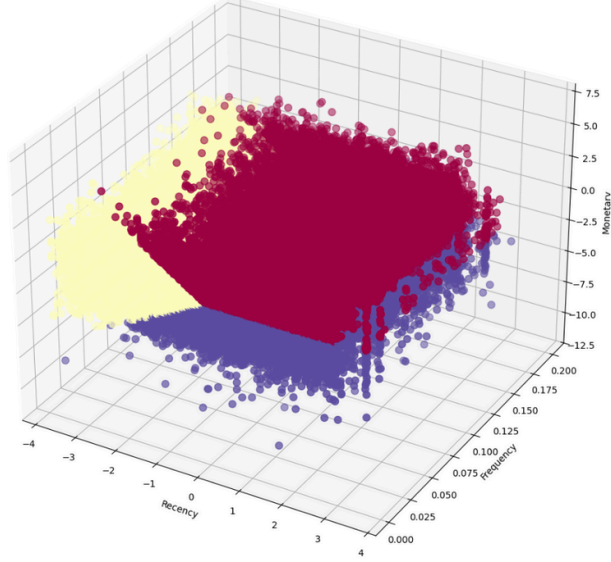
해당 모델의 시각화는 다음과 같았다.

나아가 더 세분화된 고객 군집을 통해 고객의 특성을 더 세밀하게 파악하기위해 K 값을 변환해 보았다.
그 결과, 비록 실루엣 점수는 조금 떨어지지만 여전히 바닐라 모델의 최고 점수보다는 높았기에,
군집 수를 5로 정해 분석을 계속했다.
고객 군집 별 특성 파악

| 군집 | Recency 상대 점수 |
Freuquency 상대 점수 |
Monetary 상대 점수 |
Total | Rank | 분류 |
| 1 | 5 | 3 | 5 | 13 | 1 | 우수 |
| 2 | 2 | 5 | 3 | 10 | 3 | 중요 |
| 3 | 3 | 1 | 3 | 7 | 4 | 떠나간 |
| 4 | 1 | 2 | 1 | 4 | 5 | 떠나간 |
| 5 | 4 | 4 | 4 | 12 | 2 | 우수 |
K = 5일 때의 군집 별 RFM 특성을 상대 점수로 나타내면 위와 같다.
나아가 분석의 편의를 위해 이를 다시 우수, 중요, 떠나간 고객들로 나눌 수 있었다.
1. 떠나간 고객들
먼저 떠나간 고객들은 상대 점수 합산 랭크에서 하위에 랭크되었던 집단들이다.
3번 군집은 일명 "이미 떠난 그룹", 4번 군집은 일명 "찍먹파"라고 명명을 했고,
군집 이름에서 알 수 있듯 이들은 이탈 고객들이라고 볼 수 있다.
"이미 떠난 그룹" 고객들의 경우 배송시간이 어느정도 걸렸던 문제도 있었고,
"찍먹파" 고객들의 경우 거의 시스템을 접하자 마자 떠난 분류들로
종합적으로, 이들을 위한 이미지 개선 홍보 등이 우선시 될 것 같았다.
2. 우수 고객들
다음 우수 고객들은 랭크에서 상위권에 있던 고객들이다.
1번 군집은 일명 "꽉 잡아" 그룹으로,
가격대가 있는 물건들을 자주 사는 고객들로, 비교적 인구 수가 적은 도시에서,
느리지 않은 배송 시간에 만족하는 고객들로 예상되었다.
5번 군집은 일명 "충성 고객"들로, 구매력, 구매 빈도, 최근성 모두 우수한 고객들이었다.
인구수가 많은 지역에 분포해있음에도 배송시간이 제일 빨랐기에
본 시스템에 매력을 느낀 고객들 보이고,
해당 시스템을 파악해 전체 배송 시간을 이 클러스터 만큼 개선해줄 필요도 있어보였다.
3. 중요 고객
다음은 가장 잠재성이 뛰어난 2번 그룹, "중요 포텐셜 그룹"이다.
랭크에서도 중간이었던 본 그룹은 구매력은 비교적 약하지만 가장 최근에 본 시스템을 접한 고객들로,
새로운 유입층이라고 볼 수도 있었다.
이 중요 포텐셜 그룹은 인구수가 제일 많은 도시에 분포해,
배송 시간이 좀 걸리는 문제를 역시 갖고 있는데,
이런 문제들을 해결하느냐에 따라
"떠나간 고객층"으로 내려 갈수도,
"우수 고객층"으로 올라갈수도 있는 잠재력이 있었다.
2. 지역 별 군집
머신러닝 군집 모델 선발
RFM에서 Frequency 지표가 가지는 분포가 너무 치우처져 있었기에,
이를 다방면에서 볼 필요가 있었고, 그래서 고객 별 군집 외에도 지역 별 군집을 다시 실행했다.
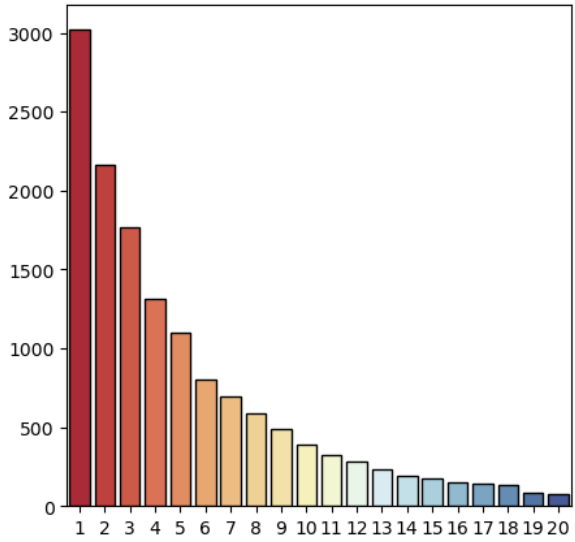
그 결과, 고객 별로 봤을 때 좌측에 심하게 쏠려있던 Frequency 지표의 분포가
지역 별로 확인하니 많이 완화됨을 볼 수 있었다.
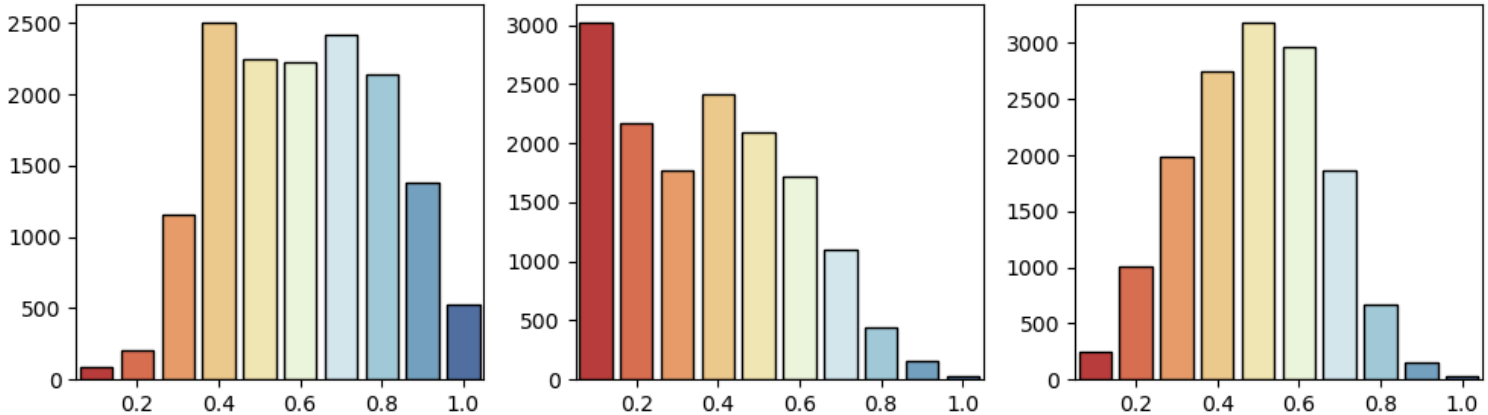
이들을 다시 Boxcox Transformation과 MinMax Scaling을 통한 전처리 과정을 거쳤고
그 결과 고객 별 RFM 보다 훨씬 가우시안 분포에 가까운 분포들을 가진 자료들을 얻을 수 있었다.
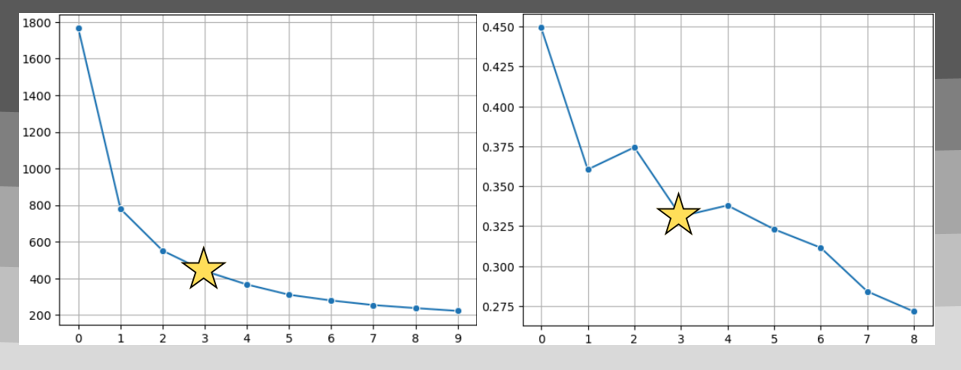
위의 전처리 된 RFM 지표들을 통해 군집을 진행했으며, 방법은 K-Means으로 였다.
최적 군집 수를 찾기 위해 WCSS 엘보우 그래프 및 실루엣 스코어들을 확인했으며,
그 결과 이상적인 k값은 2로 추정되었으나,
군집 수가 늘어남에 따라 응집도가 지속적으로 증가하고
다수의 군집 간 차이를 다양하게 분석하기 위해 최종 군집 수를 k=3으로 결정했다.
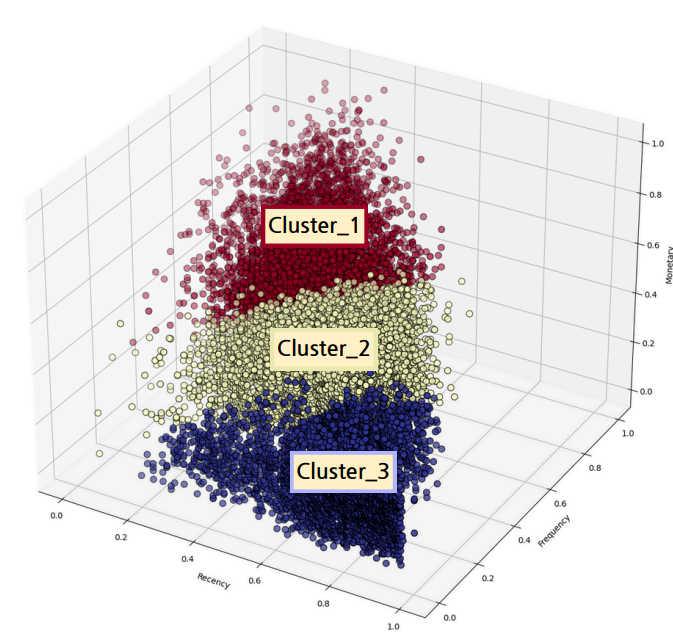
이를 통한 k-means 클러스터링 결과의 시각화는 위와 같으며
1번 클러스터는 RFM이 모두 우수,
2번 클러스터는 보통 수준,
3번 클러스터는 전반적으로 RFM이 미흡했다.
고객 군집 별 특성 파악
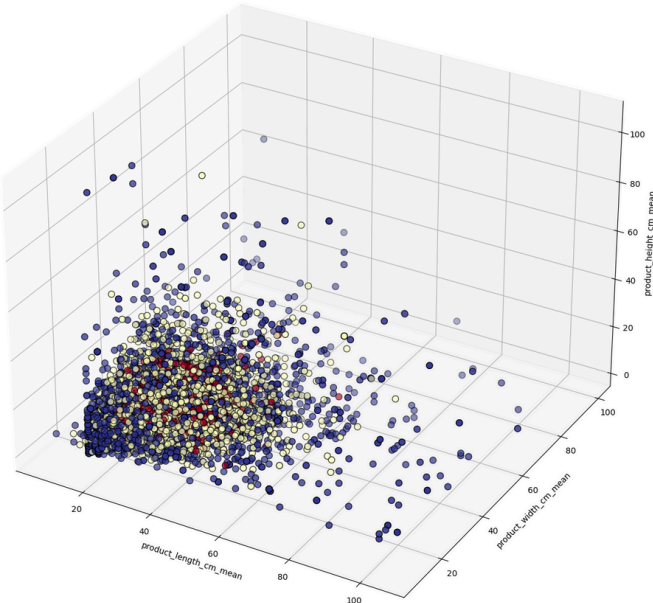
위는 새로운 지역 별 클러스터를 바탕으로 본 군집별 구매 상품 규격 데이터를 시각화 한 것이다.
구매 상품은 평균 규격에 차이는 크지 않았으나, 군집 3의 경우 규격의 편차가 매우 큰 것으로 나타났다.
즉, 군집 3에 속하는 지역의 고객은 구매하는 상품의 규격이 매우 상이하여 배송에 어려움이 있을 것으로 판단되었다.
나아가, 군집 별 EDA를 통해
지불 금액 및 신용카드 사용비중 → Custer_1이 다수
직불카드, 바우처 사용비중 → Cluter_2가 다수
지갑 사용 비중 및 배송기간 → Cluster_3이 다수
인 것으로 나타났다.
3. 액션플랜 제안
우리는 액션플랜을 제안하기 앞서, 고객 별 군집과 지역 별 군집의 공통점을 파악하고
두 데이터를 통합하기로 했다.
| 지역 구분 | 지역 Cluster 1 | 지역 Cluster 2 | 지역 Cluster 3 | ||
| 고객 구분 | 고객 Cluster 1 (꽉 잡아 그룹) |
고객 Cluster 5 (충성 고객 그룹) |
고객 Cluster 2 (하이 포텐셜 그룹) |
고객 Cluster 3 (이미 떠난 그룹) |
고객 Cluster 4 (찍먹 그룹) |
| Recency | 보통 | 높음 | 아주 높음 | 아주 낮음 | 낮음 |
| Frequency | 아주 높음 | 높음 | 보통 | 보통 | 아주 낮음 |
| Monetary | 아주 높음 | 높음 | 낮음 | 보통 | 아주 낮음 |
| 주된 결제 수단 | 신용 카드 | 직불 카드, 바우처 | 전자 지갑 | ||
| 상품 규격 표준편차 | 작음 | 보통 | 큼 | ||
| 배송 기간 | 약 12 일 | 약 13일 | 약 15일 | ||
| 액션 플랜 개요 | 프로모션 Point | 대안 제시 Point | 고객 불만 Point | ||
지역 클러스터 1에 속한 고객그룹은 구매력이 매우 높아 향후 지속적으로 구매력을 유지시킬 필요가 있는 그룹이다.
해당 그룹에는 판매 프로모션을 제공하는 방안을 제시하고자 했다,
지역 클러스터 2에 속한 고객그룹은 구매 빈도나 구매력이 낮으나 향후 충성고객으로 전환할 가능성이 있는 고객들이다.
해당 고객에게는 향후 구매력을 높일 수 있는 대안을 제공하고자 했다.
지역 클러스터 3에 속한 고객그룹은 본 이커머스의 서비스를 거의 이용하지 않는 그룹이다.
우리는 고객만족도 제고를 위해 해당 그룹에서 불만요인을 찾아 개선점을 제안하고자 했다.
1. 그룹 별 프로모션 제안
이를 모두 총합해 다시 세 분류 나누고,
분류별 액션플랜을 제시하자면 아래와 같다.
| 구분 | Cluster 1 충성 고객형 |
Cluster 2 일반 고객형 |
Cluster 3 이탈 고객형 |
| 마케팅 전략 |
프로모션을 통한 장기적 관계 형성 | 충성고객 전환을 위한 대안 제시 | 불만 요인 개선을 통한 재구매 촉진 |
| 세부 내용 |
|
|
|
2. 지역 별 배송 시스템 개선안 제안
지역 별 군집 데이터를 시각화해 지도에 위치를 표현하면 아래와 같다.
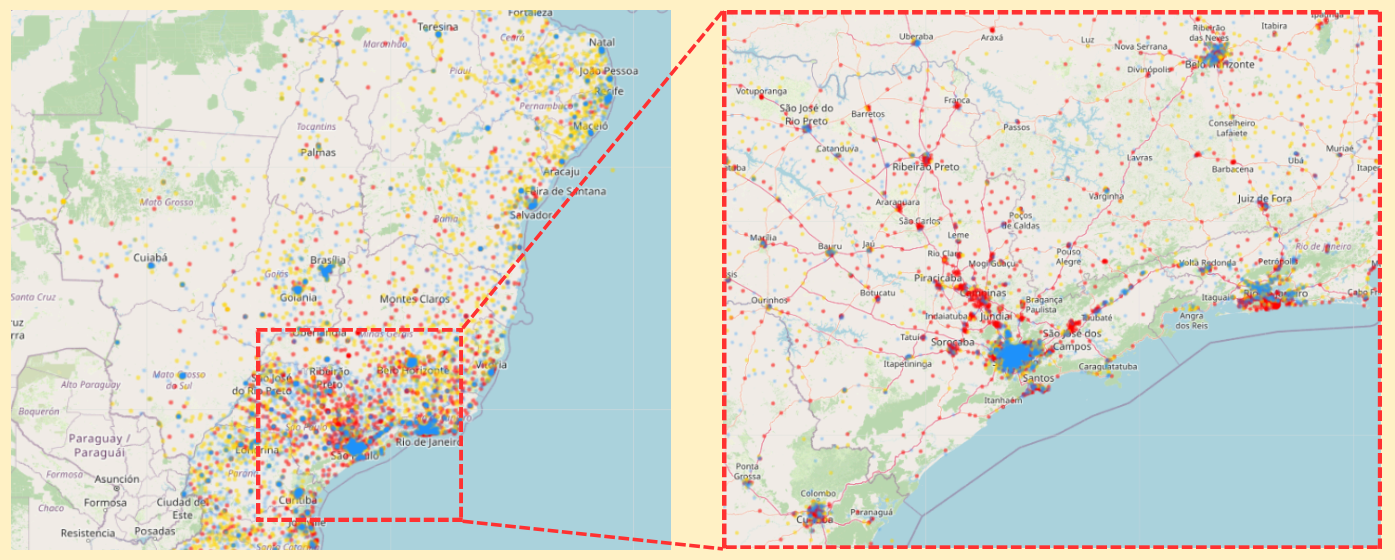
전체적으로, 상파울루나 리우데자네이루같은 대도시에는 모든 그룹이 크게 분포하는 것으로 확인되었다.
세부적으로는, 대도시의 주변 도시에는 적색으로 표기된 그룹 1과 파란색으로 표기된 그룹 3이,
내륙을 포함한 중소 도시에는 노란색으로 표기된 그룹 2가 주로 분포하는 경향이 확인되었다.
즉, 구매력이 크고 균일한 상품을 주문하는 그룹 1은 대도시 및 주변 도시에 주로 분포하는 것으로 파악할 수 있었으며
불만요인이 가장 많은 그룹 3은 주로 대도시에 분포하는 것으로 확인할 수 있었다.
따라서 소형 차량을 대도시 및 주변도시에 다수 배차하여 그룹 1의 주문수요에 대응하며,
그룹 3의 배송기간 단축을 위해서는 물류센터를 대도시 근처에 건설할 필요가 있는 것으로 판단할 수 있었다.
마치며
1. 종합하자면...
우리 프로젝트의 주요 내용은 다음과 같았다.
- 데이터가 심하게 치우친 데이터였고, 이를 감안해 적절한 전처리와 집계 방법을 두 가지로 달리 했다는 점
- 이를 기반으로 K-means 군집분석을 활용해 RFM 군집을 실행했다는 점
- 고객 별로 5개, 지역 별로 3개의 군집을 산출해 결과를 종합했다는 점
- 종합 결과를 기반으로 수익성과 고객만족성 증진을 위한 액션플랜을 제안했다는 점
2. 한계점은...
먼저 데이터 전처리 단계에서의 한계점이 있었다.
이터가 심하게 편향된 경우, 분석에 사용할 컬럼을 결정하는 과정과 전처리에서의 기술적 미흡함이 있었고,
데이터의 편향이 제대로 해소되었다면 더 나은 군집화가 이루어졌을 수 있을 것 같다.
다음은 모델링에서의 한계점이 있었다.
RFM 변수 만을 사용해 군집을 진행하면 생각만큼 다양한 특성의 클러스터가 나오지 않는다는 점이 있었다.
더 여러 컬럼들을 복합적으로 활용해 클러스터 별 특성을 최대화 해보고,
DBSCAN 같은 다른 알고리즘을 활용해 아웃라이어의 특성을 봐볼수도 있었을 것 같다.
'Projects' 카테고리의 다른 글
| [P2.1_Wow the Brazil] 브라질 이커머스 데이터와 RFM 군집 분석 (6) | 2024.09.03 |
|---|---|
| [P1_기본 프로젝트] Spotify 고객 분위 별 맞춤 전략 제시안 (4) | 2024.09.03 |