프로젝트 개요

프로젝트에 들어가기 앞서, 우리 팀은
"브라질 이커머스 기업을 인수한 쿠팡의 현지에서의 기업가지 제고를 위한 데이터 분석"
을 맡은 분석가들이라고 페르소나를 정했다.
나아가 해당 데이터들을 기반으로 브라질 고객들을 군집하고
군집 별 아이디어를 도출하는 것을 최종 목적으로 했다.
문제점
가설과 목적
분석 절차
이번 프로젝트는 위와 같은 절차로 이루어졌다.
데이터 전처리 및 EDA
1. 데이터 병합
먼저 위와 같이 기본으로 주어진 5개의 테이블과, 외부에서 따로 얻은 2개의 데이터를 병합하는 과정을 가졌다.
외부 데이터는 customer_city, 즉 도시 이름으로 분류 되어있는 도시 별 인구수 (population) 자료와
zip_code, 즉 우편 변호로 이루어진 위도와 경도 (geolocation) 자료였다.
2. 결측치 처리
위 처럼 order_delivered_timestamp, 즉 배송 완료 시각 컬럼과
product_category_name, 즉 구매 상품 카테고리에 결측치가 있었으며
배송 완료 시각 컬럼의 경우 배송상태 (order_status)가 "배송 완료"가 아닌 경우 결측치가 발생했다.
배송이 완료된 주문 건수들만을 대상으로 분석을 진행하기 위해 해당 결측치는 모두 삭제했으며
구매 상품 카테고리의 경우 최빈값인 "Toy (장난감)"으로 대체하였다.
3. 명목형 데이터 인코딩 및 파생변수 생성
분석에 사용할 지표들인 "payment_type (지불 방법)"은 One Hot Encoding을 통해,
미국처럼 연방 국가로 되어있어 "주"가 있는 브라질 속 "고객들의 거주지역 (주)"는 Label Encoder를 통해
인코딩 해주었다.
4. 파생변수 생성
분석에 추가적으로 사용할 파생변수들은 위와 같이 생성했다.
5. EDA - 심하게 치우친 분포들



이번 데이터는 많은 부분에서 굉장히 치우친 분포를 보였다.
가격, 배송비, 지불비용은 왼쪽으로 심하게 치우친 파레토 분포를 따르고 있었고,
구매 횟수 분포의 경우 그 치우침이 훨씬 더 심했다.
이런 치우침은 수치형 데이터에서만 볼 수 있는 형상이 아니었으며, 이를 해결하기 위해 우리는
지역별, 고객별로 데이터를 집계하는 등 다방면으로 데이터를 분석할 필요성을 느꼈다.

위는 치우친 여러 지표들의 박스 플랏의 결과이며,
상당히 작은 박스가 왼쪽에 그려지며, 이로인해 많은 자료들이 4분기에 포함되게 된다.
이렇게 데이터의 편향, 치우침이 심한 자료들에서 이상치를 정의하기란 쉽지 않았고,
4분기, 혹은 그 이상의 포인트들을 모두 이상치로 판단해 삭제한다면,
일반적으로 납득 가능한 수치들이 대거 삭제될 것으로 예상되어 이상치 처리는 하지 않았다.
하지만 이 부분에서 더 나은 결측치 처리 기준이 필요했을 것 같으며
삭제 하지 않는다면 왜 하지 않았는지에 대한 통계적 유의성을 제시하던지,
IQR 결측치 제거를 더 Strict하게 실행해 아웃라이어를 제대로 검출해 삭제를 한다던지 하는
더 그럴듯한 근거를 댔어야 한다고 생각한다.
6. EDA - 상관관계

위는 변수들의 선형 적 상관관계를 히트맵으로 본 것이며,
상품 가격과 배송비,
배송비와 상품 무게,
실제 지불 금액과 상품 가격에서
높은 상관관계를 볼 수 있었다.
RFM 변수 정의
지난 프로젝트에서 명목형 데이터만을 활용해 RFM을 진행했던 것 과는 달리,
이번에는 제대로 수치형 데이터들을 가지고 RFM을 진행할 수 있었다.
우리는 주어진 데이터에서 고객 별로
가장 마지막 구매 일, 총 구매 건수, 구매 당 평균/총 지불 금액을 알 수 있었고,
이를 통해 각각 R과 F와 M을 구할 수 있었다.
Recency의 경우 고객 별 가장 마지막 구매일로부터 기준 시간까지의 경과 시간을 통해 구했고
Frequency의 경우 고객 별 구매 건 수를 통해 알 수 있었고
Monetary의 경우 여러 금액 지불 지표를 통해 고객 별 구매 평균/총 지불 금액을 통해 구했다.
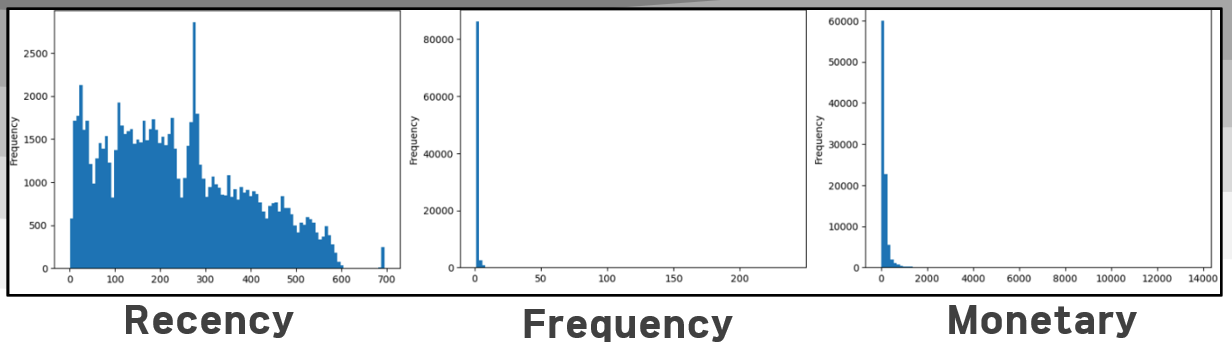
그 결과 위와 같은 분포를 가진 각 지표를 구할 수 있었다.
Recency의 경우 비교적 고루 분포되어 있음을 볼 수 있었지만,
Frequency와 Monetary의 경우 심하게 치우친 형상을 보고, 특히 Frequency가 그 정도가 매우 심했다.

그래서, 각각의 분포를 해결하기 위해 다음과 같은 스케일링과 변환 과정을 거쳤다.
모든 지표들은 Boxcox 변환을 통해 각각의 분포 그래프에 맞는 변환 가정을 거쳤고,
나아가 Standard Scaling을 통해 Recency와 특히 Monetary가 가우시안 분포에 근접해짐을 볼 수 있었다.
Frequency의 경우 대도시에서의 주문량이 특히 더 많은 브라질의 특징을 RFM에 반영하고자,
그리고 무엇보다 그래프의 쏠림을 완화하고자 각 빈도수에 도시 인구수를 곱했고,
다음과 같이 치우친 분포를 어느정도 완화할 수 있었다.
분석 결과는 다음 포스트에 ...
'Projects' 카테고리의 다른 글
| [P2.2_Wow the Brazil] 브라질 이커머스 데이터와 RFM 군집 분석 (5) | 2024.09.03 |
|---|---|
| [P1_기본 프로젝트] Spotify 고객 분위 별 맞춤 전략 제시안 (4) | 2024.09.03 |